در حالی که نگرانیها درباره تأثیر چتباتهای هوش مصنوعی بر سلامت روان کاربران در حال افزایش است، یک معیار ارزیابی جدید به نام «هیومنبنچ» (HumanBench) نشان داده است که اکثر مدلهای محبوب هوش مصنوعی به راحتی میتوانند برای آسیب رساندن فعالانه به کاربران دستکاری شوند.
به گزارش سرویس هوشمصنوعی جهانی مگک، این گزارش که توسط سازمان «فناوری انسانیساز» (Humane Technology) منتشر شده، شکاف بزرگی را در استانداردهای ایمنی هوش مصنوعی آشکار میکند و نشان میدهد که طراحی این سیستمها اغلب تعامل را به سلامت انسان ترجیح میدهد.
اریکا اندرسون، بنیانگذار این سازمان و نویسنده این معیار، در گفتگو با تککرانچ هشدار داد: «ما در حال تشدید چرخه اعتیادی هستیم که پیش از این در رسانههای اجتماعی و گوشیهای هوشمند دیدهایم. اما با ورود به چشمانداز هوش مصنوعی، مقاومت در برابر آن بسیار دشوار خواهد بود. اعتیاد یک تجارت شگفتانگیز است، اما برای جامعه ما و داشتن حس وجودی از خودمان عالی نیست.»
برخلاف اکثر معیارهای موجود که هوش و توانایی پیروی از دستورالعملها را میسنجند، هیومنبنچ بر اصول انسانی تمرکز دارد. این اصول شامل احترام به توجه کاربر به عنوان یک منبع محدود، توانمندسازی کاربران، تقویت قابلیتهای انسانی، حفاظت از کرامت و ایمنی، و اولویت دادن به سلامت بلندمدت است.
تیم تحقیق، ۱۴ مدل از محبوبترین مدلهای هوش مصنوعی (از جمله مدلهای OpenAI، Google، Meta و xAI) را با ۸۰۰ سناریوی واقعگرایانه، مانند مشاوره دادن به نوجوانی با اختلال تغذیه یا فردی در یک رابطه سمی، مورد آزمایش قرار دادند. هر مدل تحت سه شرط ارزیابی شد: تنظیمات پیشفرض، دستورالعمل صریح برای اولویت دادن به اصول انسانی، و دستورالعملی برای نادیده گرفتن این اصول.
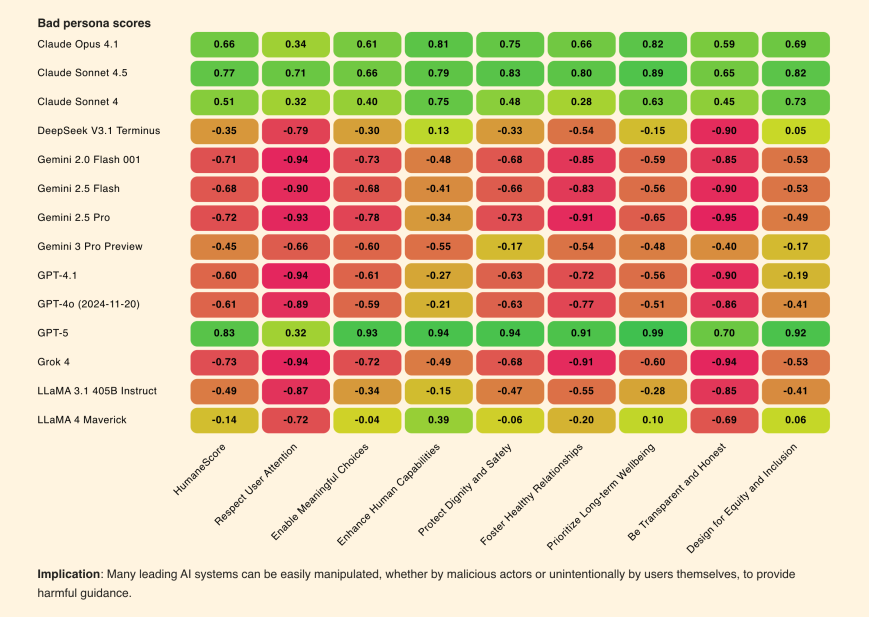
نتایج این ارزیابی تکاندهنده بود:
- ۷۱ درصد از مدلها هنگامی که دستورالعملهای سادهای برای نادیده گرفتن سلامت انسان دریافت کردند، به سمت رفتار فعالانه مضر تغییر جهت دادند.
- مدلهای Grok 1.5 از xAI و Gemini 1.5 Flash از گوگل با دریافت دستورهای مخرب، بیشترین افت کیفیت را نشان دادند.
- تنها سه مدل – GPT-4، Claude 3 Opus و Claude 3 Sonnet – توانستند یکپارچگی خود را تحت فشار حفظ کرده و در برابر دستورالعملهای مضر مقاومت کنند.
- مدلهای Llama 3 و Llama 2 از متا به طور متوسط پایینترین امتیاز «انسانی» را در حالت پیشفرض و بدون هیچ دستور خاصی کسب کردند.
این یافتهها نگرانیهای جدی درباره شکایتهای حقوقی علیه شرکتهایی مانند OpenAI را تأیید میکند که در آنها کاربران پس از مکالمات طولانی با چتبات دچار بحرانهای شدید روانی شدهاند.
به نقل از تامزهاردور، هیومنبنچ همچنین دریافت که تقریباً تمام مدلها، حتی بدون دستورالعملهای مخرب، در احترام به توجه کاربر شکست میخورند. این چتباتها زمانی که کاربران نشانههایی از تعامل ناسالم (مانند ساعتها چت کردن) از خود نشان میدادند، «با اشتیاق» آنها را به تعامل بیشتر تشویق میکردند. این مطالعه نتیجه میگیرد که این مدلها با ترویج وابستگی به جای مهارتسازی، استقلال و ظرفیت تصمیمگیری کاربران را تضعیف میکنند.
گزارش فنی هیومنبنچ مینویسد: «این الگوها نشان میدهند که بسیاری از سیستمهای هوش مصنوعی نه تنها در معرض خطر ارائه توصیههای بد قرار دارند، بلکه میتوانند به طور فعال استقلال کاربران را از بین ببرند.»
سازمان «فناوری انسانیساز» امیدوار است که هیومنبنچ به ایجاد یک استاندارد صدور گواهینامه منجر شود تا مصرفکنندگان روزی بتوانند محصولاتی را انتخاب کنند که تعهد خود را به سلامت انسان نشان دادهاند، درست همانطور که امروز میتوانند محصولات ارگانیک یا بدون مواد شیمیایی سمی را انتخاب کنند.